In a standard Postgres benchmark, my own $1500 Thinkpad laptop outperforms a $9,000 per-month cloud database on Amazon RDS, as shown in the following benchmark:
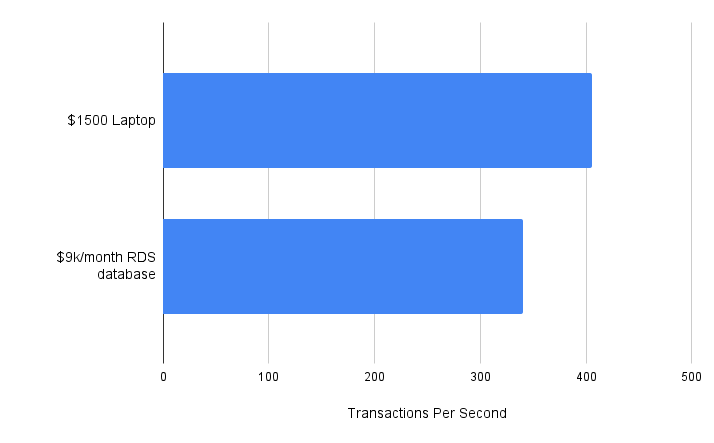
This incredible fact begs the question: How come that despite the advancements in cloud infrastructure and storage technology, our databases are slower and more expensive?
This problem is so prevelant that a whole generation of engineers has come to believe that SQL databases are inherently slow and inefficient.
In many cases the answer lies in a not-so-well-understood term: IOPS.
What is IOPS?
IOPS (Input/Output Operations Per Second) is a metric used to measure the performance of storage devices such as hard disk drives (HDD) and solid-state drives (SSD). It quantifies the number of read and write operations a device can support per second.1
IOPS becomes a bottleneck in databases when running disk-heavy workloads. For instance, when a read query is executed in Postgres, it reads 8KiB pages from disk until it finds the relevant entry, either from an index file (index scan), a table file or both. Each page read can result in an I/O operation, thus consuming the disk’s IOPS capacity.
Postgres and the Linux kernel both attempt to cache frequently-used pages to reduce I/O operations. However, this cache is limited to the size of the machine’s memory. IOPS becomes a bottleneck when either:
- The database contains a very large table or index that does not fit in memory;
- The database contains many smaller tables and indexes and needs to constantly change which one is cached in memory;
- The database has a high write workload (each database write results in a write operation to the WAL file);
- The database runs certain queries (like
ORDERY BY) that make use of temporary files on disk.
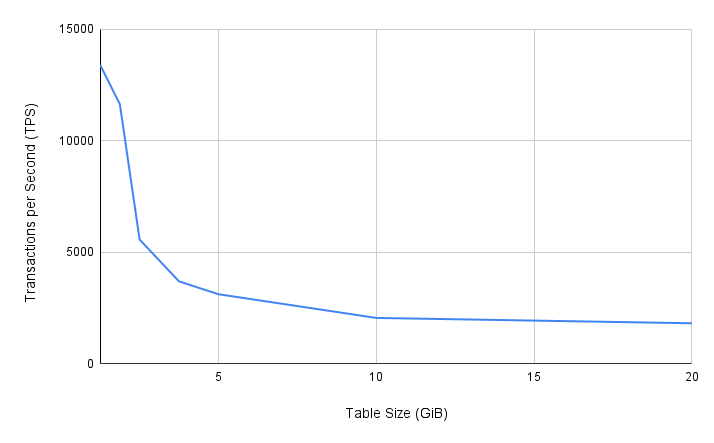
An IOPS bottleneck can be easily observed in the following Postgres benchmark on RDS2. As the table size increases, it cannot be effectively cached in memory and the transaction-per-second rate (TPS) decreases due to the IOPS limit that RDS imposes.
Cloud IOPS is limited and expensive
The fact that my laptop outperforms a $9,000 per-month RDS database is because IOPS in cloud environments is either limited, or very expensive.
To get a sense just how expensive it is, we can compare it to household SSD devices. My laptop, for example, clocks in at about 100k random read IOPS using 8KiB blocks3. A $120 Samsung 870 EVO SSD supports about 100k random read IOPS as well. A $290 Samsung 990 Pro SSD claims to reach 1.4M IOPS.
But on the cloud it’s a whole different story. To run a Postgres database with 100k IOPS on Amazon RDS, you would need to pay just shy of $130k per year. And reaching the maximum of 256k IOPS would cost upwards of $300k per year!4 (and double that if you want multi-AZ deployment).
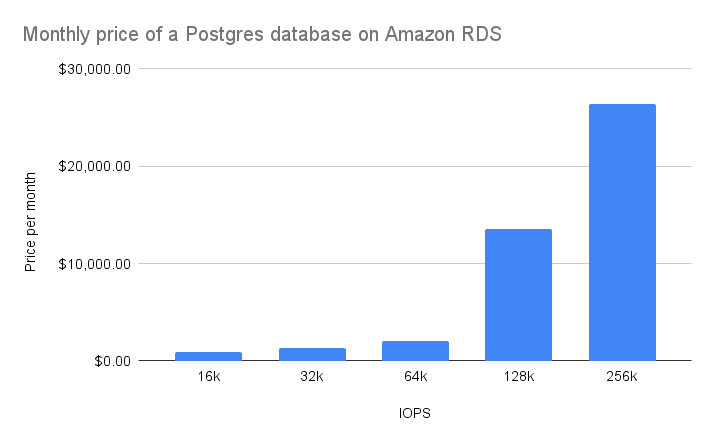
Note: These numbers differ across cloud providers.
On AWS, IOPS is controlled directly with the relevant pricing shown above.
Up to 64k IOPS, RDS uses gp3 storage volumes that have a decent price of $0.005/IOPS.
Above that requires using the highly-expensive io1 storage that costs 13 times more, and this is where the price really starts to inflate.
On GCP, IOPS is indirectly determined by the amount of storage. It is limited only up to 100k IOPS, which costs “just” $3k/month.
Why is cloud IOPS so expensive?
The short answer is - the separation of storage and compute.
Separating the database storage from where the database engine itself runs has been the trend since the first days of the cloud. Cloud vendors invested years of research and engineering into it, with two major generations shown below.
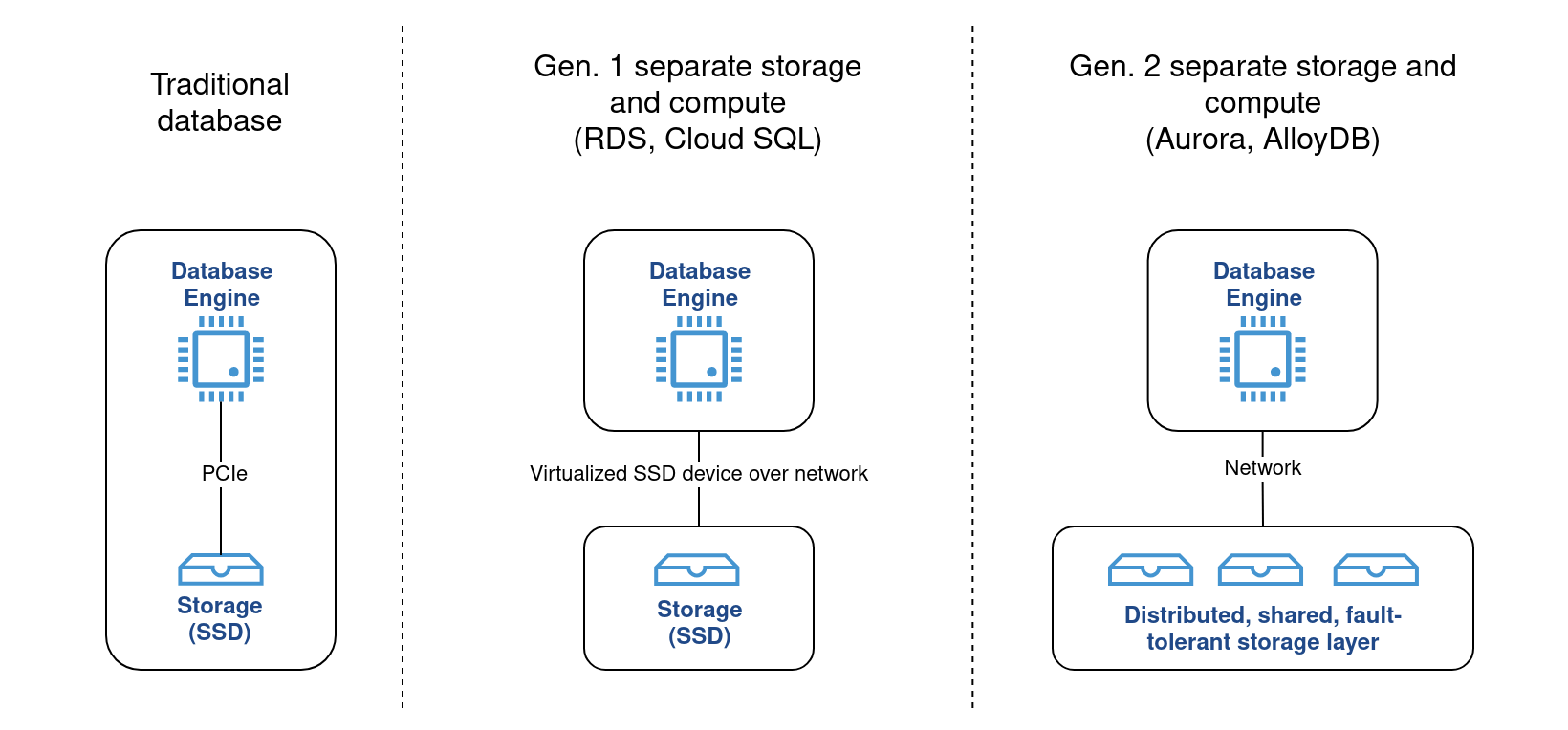
The benefits of this architecture mostly revolve around simplifying database management tasks. Upgrading database versions, increasing storage capacity, setting up replicas and handling crash-recovery - once error-prone tasks for a DBA - are now a simple click away or completely automated. And it’s mostly made possible because the storage is physically disconnected from the compute engine. This separation, however, comes at a cost - and that cost is often reduced IOPS capacity.
Looking again at RDS, Amazon’s managed relational database service, the database storage is based on EBS volumes - virtualized storage devices that are backed by real SSDs but connect to the compute instance over the network. Because the storage layer is shared by all of Amazon’s customers, and it communicates over the network, it is much more limited in IOPS capacity. On top of that, to support more IOPS, the compute instance itself requires larger network bandwidth, which necessitates using more expensive instances.
By using any of the managed database offerings, we are trading performance and cost for ease-of-use and fault tolerance.
Techniques to overcome the IOPS bottleneck
The IOPS limitation in the cloud is so acute and common that almost every engineering team that I know which works on SaaS products at scale has suffered at some point from IOPS bottlenecks.
Unfortuantely, there is no magic wand.
The following is a list of common techniques used to overcome the limitation, in order of their engineering difficulty:
- Provisioning more IOPS. This is obviously the easiest way, usually a click away in the cloud console. It is not necessarily a bad option - the other options require large engineering overhead and expertise. On AWS for example, you can reach 64k IOPS at a decent price using 4
gp3storage devices in a RAID 0 array. - Setting up read replicas. Read replicas for databases help scaling read workloads with minimal effort. Launching a read replica is a simple task thanks to the cloud providers. There is complexity involved, however, on the applicative side. Engineers have to decide how to route read requests (whether to the primary or the replica) and how to overcome data inconsistencies due to replication lag. In addition, a replica will basically double the database cost, and might waste a lot of IOPS just on performing the replication itself - not leaving much extra IOPS capacity for additional read load.
- Query optimization. When the easy solutions begin hitting a wall as well (or just cost tons of money), there is no way of avoiding the gruelling task of query optimization. Usually this involves adding lots of indexes. And indexes come with their own problems - an index on a table might reduce the read IOPS, but increase the write IOPS instead.
- Sharding the database. Multiple separate databases can have total provisioned IOPS at a much better cost than a single large database. A common pattern in multi-tenant applications is to shard tenants across multiple database instances. The reason this can be done relatively easily is because there are no cross-tenant workloads in the database. Vitess is such a solution for MySQL. For Postgres, there is a great article by Notion about their architecture.
- Using a different database. Usually the last resort option, but often unavoidable. Some queries just use too much IOPS. A common pattern is to use use a secondary database for certain queries. For example, an OLAP database like ClickHouse can calculate a column average much more efficiently than Postgres because of its columnar storage format. The challenge that arises then is how to replicate the data into the secondary database and keep it in sync with the source of truth.
New approaches might become the standard
There are multiple interesting ideas being worked on in the database space that, if proven to work well, will help overcome the IOPS limitation without the huge engineering effort usually involved:
- Database caching engines. Modern caching engines can cache the results of common queries and keep these results up-to-date automatically as the underlying data changes. Using a cache can dramatically reduce the amount of disk access needed to serve read queries. Companies like ReadySet and PlanetScale are working on this.
- Incremental computation engines.
Even simple queries might require accessing GBs if not TBs of disk data.
For example, a simple calculation of a table average (
SELECT avg(field) FROM table) requires a full table scan. Incremental computation engines can maintain the results of these queries continuously, only processing the changes to the underlying data. Thus, no large disk scans are required. Materialize is currently building this. - Local SSD cache. Using a local SSD device as an extension to the database’s in-memory cache. Local SSD devices are physically integrated into the compute instance and have lots of cheap IOPS. These devices do not persist crashes, however, so they can be used as a cache but not as the database’s primary storage. Google recently released Cloud SQL Enterprise Plus and claims to achieve 3x better read throughput using this technique.
Whether these new ideas can overcome current limitations easily and cost-effectively remains to be seen.
A final thought: tightly-coupled storage and compute?
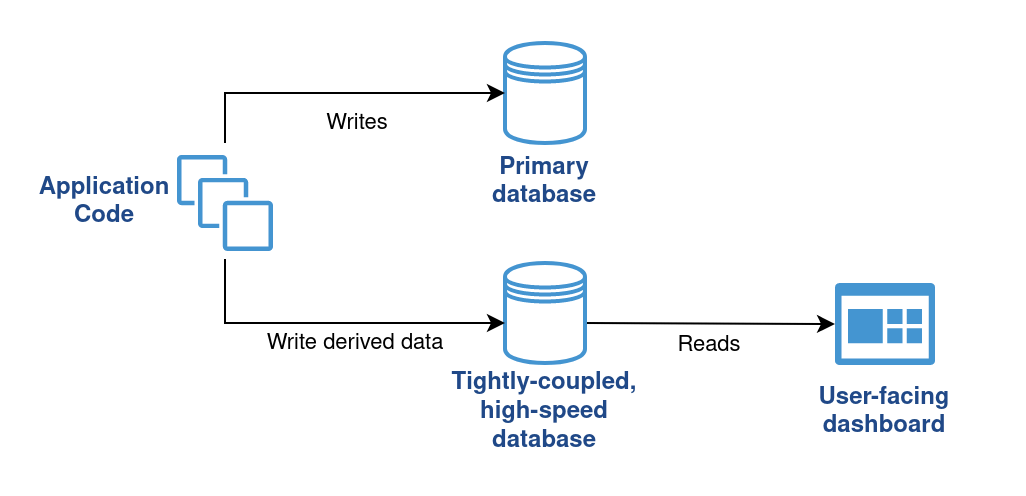
While the trend in the cloud era has always been to separate storage and compute, it may be worthwhile to reconsider this architecture. Is there a place for a tightly-coupled, highly-performant system alongside current setups? Some workloads do not require instant failover or infinite storage capacity, which separate storage offers.
Cosider a read-only workload on top of derived data:
- Data loss can be mitigated by re-deriving the data from the source of truth.
- The derived data is usually more compact in size.
A common example is a user-facing dashboard. This dashboard may display, for example, only aggregated statistics and only from the last 30 days. We can store the dashboard’s data in a tightly-coupled database that is significantly more cost-effective and performant. In addition to a better user experience, we also benefit from the fact that the primary database holding the source of truth has much less processing to perform in terms of indexing and serving the derived data.
Do you have more examples of such workloads, or experience in building one? Feel free to share your thoughts.
Footnotes
Footnotes
-
SSD vendors usually publish 4 different IOPS stats: Random read, random write, sequential read and sequential write. Sequential reads and writes are sometimes referred to as ‘bandwidth’ and measured in MB/s. ↩
-
Using
pgbenchread-only benchmark on a small RDS database with 4GB of memory. ↩ -
On a Linux machine it is possible to measure the random read IOPS by using the
fiocommand. Examples can be found here. ↩ -
Using Amazon RDS for Postgres,
db.m4.2xlarge,io1storage with 100-256k provisioned IOPS and 2TB storage. Check it out for yourself. ↩